데이터분석 프로젝트 (feat. LightGBM, XGBoost, RF)
SMILES Code를 기반으로 해당 화학 물질이 독성 물질인가를 분석, 예측하는 모델을 구축하는 미니 프로젝트입니다.
교수님께서 주신 SMILES Code 및 성분 데이터를 기반으로 데이터의 전처리 및 모델 구축, 파라미터 튜닝까지 진행해보았습니다!
데이터 분석 및 전처리
일단 컬럼이 매우(..) 많았습니다.
SMILES 코드를 기반으로 핑거프린트를 이진법으로 표현해둬서 컬럼이 매우 많았습니다.
SMILES 코드? 핑거 프린트? 도메인 지식 먼저 챙기기..!
SMILES (Simplified Molecular Input Line Entry System) 는 분자 구조를 문자열로 표현하는 방식입니다.
컴퓨터가 화학 구조를 효율적으로 저장하고 분석할 수 있도록 설계되었습니다.
짧은 ASCII 문자열을 사용하여 화합물의 구조를 표현합니다.
Finger Print 는 분자의 원자, 결합 그리고 다양한 구조적 특성에 대한 정보를 암호화하여 분자 모델링 및 의약품 설계 분야에서 효율적인 비교와 예측을 가능하게 합니다.
즉, SMILES나 분자 구조를 숫자화해서 기계학습에 넣거나 유사도를 계산할 수 있도록 하는 것입니다.
핑거 프린트의 예시로는 ECFP(Extended-Connectivity Fingerprint), FCFP(Functional-Class Fingerprint), PTFP(Path-based Topological Fingerprint) 가 있습니다.
| 종류 | 이름 | 의미 |
|---|---|---|
| ECFP | Extended Connectivity Fingerprint | 원자 주변의 구조를 원 중심으로 확장 |
| FCFP | Functional-Class Fingerprint | ECFP와 유사하되, 화학적 역할(기능성) 기반으로 표현 |
| PTFP | Path-based Topological Fingerprint | 분자의 경로 기반 위상 구조에 따라 특징 추출 |
데이터 전처리
일단 ECFP, FCFP, PTFP 간 서로 비슷한 부분이 있었다면 세 가지 핑거프린트 중에 하나를 골라서 사용했을 것 같습니다.
근데 세 개 다 다른 정보를 담고 있었기 때문에 세 핑거프린트 모두 사용하기로 했습니다!
나머지 컬럼들에 대해서 상관 관계를 비교해보았습니다.
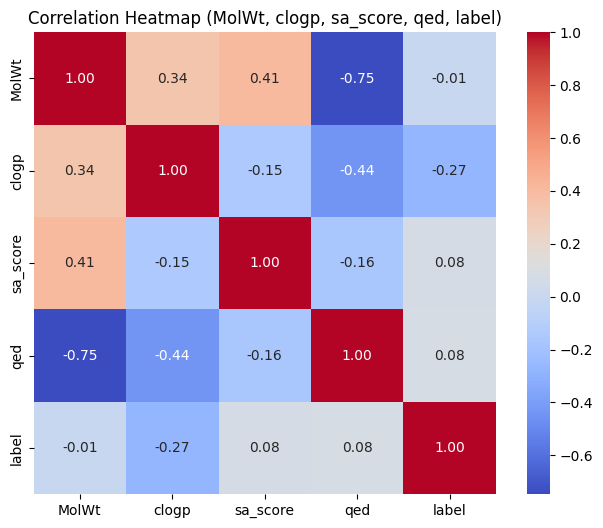
가장 상관관계가 높아보이는 것은 qed와 MolWt인데,
QED는 여러 약물유사성(desirability) 지표를 통합한 [0, 1] 사이의 점수로, 높을수록 약으로 쓰기 적합한 분자임을 의미하고,
MolWt는 분자의 원자량의 합을 의미합니다.
두 변수의 상관관계가 높게 나타나는 이유는 MolWt가 QED의 계산 공식에 포함되어 있기 때문입니다.
QED는 각 속성별 desirability function을 기반으로 log-scale 가중평균 계산을 합니다.
MolWt가 특정 범위를 벗어나면 QED 점수에 불리하게 작용하기 때문에 상관관계가 높게 나타난 것입니다.
그래도 두 변수 중 하나를 제거해야 할 정도로 상관관계가 높게 나타나지 않았으므로,
주어진 데이터베이스의 모든 컬럼을 다 사용하기로 했습니다!
각 변수의 분포도를 확인했을 때에도 거의 모든 변수가 정규분포를 따르고 있었기 때문에 따로 정규화를 하지 않았습니다.(아마 교수님께서 이미 정제된 데이터를 주신게 아닐까 싶습니다,,)
그래도!
나름대로 전처리를,,하고 싶어서,,
각 핑거프린트에서 mutual_info_score를 기준으로 label 컬럼(독성 유무 컬럼)과 상관관계가 높은 상위 250개의 컬럼들만 추출 했습니다.
mutual_info_score는 두 변수 간의 상호 정보량(Mutual Information) 을 계산하는 지표로, 한 변수의 값을 알 때 다른 변수에 대한 정보를 얼마나 얻을 수 있는지를 수치로 나타냅니다.
범주형 변수 간 비선형 관계를 나타내준다고 해서 사용해봤습니다!
사실 이 코드의 순서 자체도 중요할 것 같긴 했지만..왠지 상관 관계가 높은 컬럼을 추출하면 더 성능이 좋아지지 않을까 싶어서..이렇게 해보았습니닷
모델 구축하기
저는 총 4가지 모델의 성능을 실험해보았습니다.
로지스틱 회귀, 랜덤포레스트, LightGBM, XGBoost 를 사용해서 실험을 해봤는데
XGBoost 의 성능이 가장 좋았기 때문에 이 모델을 선택했습니다.
f1 score를 기준으로 모델의 성능을 평가하고 과적합을 지양하기 위해 교차검증도 진행했습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split, cross_val_score
from sklearn.ensemble import RandomForestClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import GridSearchCV
import xgboost as xgb
from lightgbm import LGBMClassifier
from sklearn.metrics import mutual_info_score
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
df = pd.read_csv('/content/drive/MyDrive/train.csv')
def find_top_correlated_bits(toxic_labels, columns):
correlations = []
for col in columns:
mi = mutual_info_score(df[col], toxic_labels)
correlations.append((col, mi))
correlations = sorted(correlations, key=lambda x: x[1], reverse=True)[:250]
return list(map(lambda x: x[0], correlations))
ecfp_activation_summary = summarize_bit_activation_by_label(df, ecfp_cols)
ptfp_activation_summary = summarize_bit_activation_by_label(df, ptfp_cols)
fcfp_activation_summary = summarize_bit_activation_by_label(df, fcfp_cols)
top_features = ecfp_top_10 + ptfp_top_10 + fcfp_top_10 + ['clogp', 'qed']
X = df[top_features]
y = df['label']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# XGBoost 모델 생성 및 학습
xgb_model = xgb.XGBClassifier(
n_estimators=200, # 트리 개수
max_depth=10, # 트리 최대 깊이
learning_rate=0.1, # 학습률
subsample=0.8, # 샘플링 비율
colsample_bytree=0.8, # 특성 샘플링 비율
objective='binary:logistic', # 이진 분류
random_state=42
)
# 모델 학습
xgb_model.fit(X_train, y_train)
# 예측 및 평가
y_pred = xgb_model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"XGBoost 정확도: {accuracy:.4f}")
print("\n분류 보고서:")
print(classification_report(y_test, y_pred))
# 특성 중요도 확인
importance = xgb_model.feature_importances_
importance_df = pd.DataFrame({
'Feature': X.columns,
'Importance': importance
}).sort_values('Importance', ascending=False)
print("\n특성 중요도:")
print(importance_df)
# 교차 검증
xgb_cv_scores = cross_val_score(xgb_model, X, y, cv=5)
print(f"\n교차 검증 평균 정확도: {np.mean(xgb_cv_scores):.4f}")
하이퍼 파라미터는 그리드 서치를 통해 최대한 최적의 파라미터를 찾기 위해 노력해 나온 파라미터들입니당
결과
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
XGBoost 정확도: 0.8102
분류 보고서:
precision recall f1-score support
0 0.81 0.77 0.79 778
1 0.81 0.84 0.83 892
accuracy 0.81 1670
macro avg 0.81 0.81 0.81 1670
weighted avg 0.81 0.81 0.81 1670
특성 중요도:
Feature Importance
515 fcfp_322 0.049332
500 fcfp_146 0.046641
277 ptfp_85 0.010572
0 ecfp_807 0.008975
559 fcfp_542 0.008588
.. ... ...
129 ecfp_229 0.000000
692 fcfp_557 0.000000
695 fcfp_218 0.000000
712 fcfp_882 0.000000
704 fcfp_994 0.000000
[752 rows x 2 columns]
교차 검증 평균 정확도: 0.7116
교차 검증을 해보았을 때 점수 차이가 꽤 나서 불안했는데,,
실험했을 때와 크게 다르지 않은 결과를 받을 수 있었습니다!
마치며
다른 분들은 아예 전처리를 하지 않고 파생 변수만을 만들어서 학습을 시키거나, PTFP 중 모든 컬럼에서 활성화 되어있는 컬럼을 제외시켜서 학습을 시키셨습니다
파라미터를 찾는 과정에서 조금 오래 걸려서 다른 분들이 하신 방법을 제 코드에 적용을 못 시켜본 것이 쪼오금 아쉽긴하지만
다른 분들이 하신 코드도 같이 공유해서 보면서 파생 변수의 힘이 대단하다는 것을 알게 되었습니다!
잠깐 학부 연구생을 했을 때에도 인공지능 모델 연구하는 것이 재밌다고 느꼈었는데
이번에 했던 미니 프로젝트도 너무 재미있게 진행했던 것 같습니다
모두 즐거운 코딩 생활 하세용,,!!
🤓💡
참고 자료