MSA 구현하기(12) - 마이크로 서비스에도 WebFlux 적용하기 (4) (feat. Kafka)
Skala 과정에서 마이크로 서비스 아키텍처 구조에 대해 새롭게 알게 되었습니다.
배운 것을 실제로 구현해보기 위해 이 여정을 시작하기로 했습니다.
처음 글부터 보러가기
상품 서버에서는 kafka를 통해 주문 서버에서 사용자가 주문한 상품의 Id와 수량을 전달 받아서,
재고를 감소시키는 로직이 있는데 WebFlux 방식으로 이를 리팩토링하면서, 동시성 문제도 해결 해보겠습니다!
동시성 문제란?
여러 스레드가 동시에 공유 자원에 접근할 때 발생하는 문제입니다.
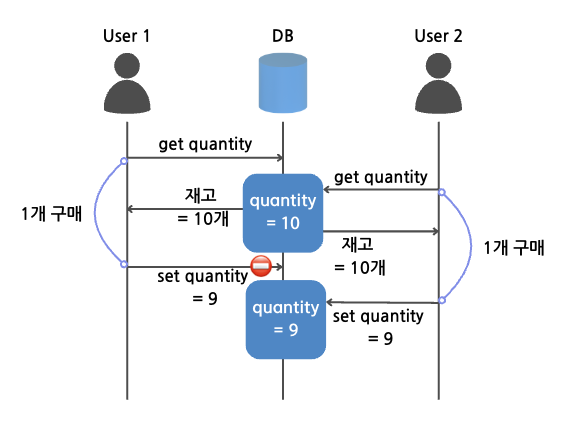
동시에 여러 사용자가 DB에 접근할 때, 다음과 같이 아직 업데이트 처리가 완전히 종료되지 않았음에도
다른 트랜잭션이 실행되어 먼저 실행된 트랜잭션의 결과가 유실되는 상황이 발생할 수 있습니다.
해결 방법
이를 해결하기 위해서는 3가지의 방법을 사용할 수 있습니다.
- 비관적 락
- 낙관적 락
- 분산 락
| 구분 | 비관적 락 (Pessimistic) | 낙관적 락 (Optimistic) | 분산 락 (Distributed) |
|---|---|---|---|
| 개념 | 먼저 락을 걸고 작업 수행 | 충돌 가능성 전제로 후 검증 | 여러 노드 간 자원 접근 제어 |
| 사용 상황 | 충돌 가능성 높을 때 | 충돌 가능성 낮을 때 | 여러 서버가 동시에 접근할 때 |
| 구현 방식 | DB의 SELECT FOR UPDATE 등 | 버전 필드 기반 비교 (@Version) | Redis, ZooKeeper, DB 등 이용 |
| 성능 영향 | 트랜잭션 길면 성능 저하 | 충돌 시 재시도 비용 발생 | 네트워크 지연, 분산 시스템 부하 |
| 충돌 처리 | 충돌 자체를 회피 | 충돌 발생 시 예외 후 재시도 | 락 선점 실패 시 대기 또는 실패 |
| 장점 | 데이터 일관성 보장 우수 | 성능 우수, 비충돌 상황에 적합 | 분산 환경에서 확장성 우수 |
| 단점 | 데드락, 성능 저하 위험 | 충돌 시 잦은 재시도 | 복잡한 인프라 필요 |
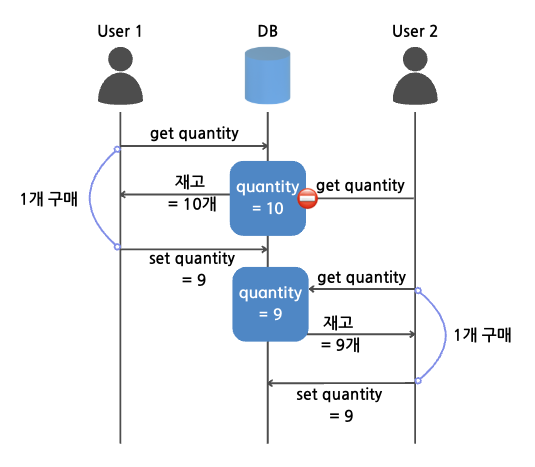
비관적 락을 통해 동시성을 제어한다면
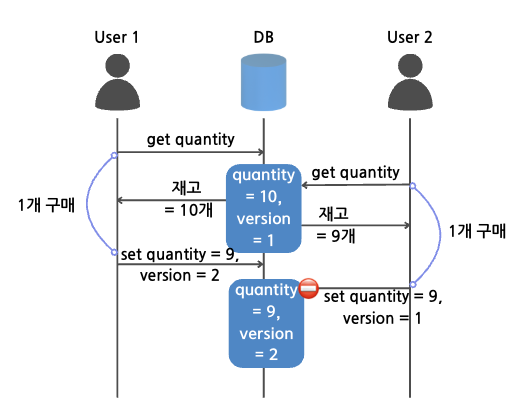
낙관적 락을 통해 동시성을 제어한다면
분산 락을 통해 동시성을 제어한다면
비관적 락과 유사하지만, 비관적 락은 한 개의 서버가 접근하는 상황에서 사용할 수 있는 기술이라면
분산 락은 여러 서버가 동시에 접근할 때 사용하는 기술입니다.
Redis가 제공하는 락 기능이 편리하기도하고, 메모리 기반 저장소이기 때문에 응답 속도가 빨라
분산 락을 위해 Redis를 주로 사용합니다.
제가 구현하고 있는 상품 서버에서 동시성을 제어하기 위해 저는 비관적 락 방법을 이용하고자합니다.
Kafka 메시지를 활용해서 재고를 관리하는 로직이기 때문에, 여러 서버에서 해당 DB에 접근하는 것이 아니라
구현이 쉽고, 정확성을 보장하는 비관적 락을 사용하기로 했습니다!
기존 코드 리팩토링
KafkaConsumer.java 리팩토링
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
@Service
@Slf4j
@RequiredArgsConstructor
public class KafkaConsumer {
private final ItemRepository itemRepository;
@Transactional
@KafkaListener(topics = "db-connection-test")
public Mono<Void> processMessage(String kafkaMessage) {
log.info("Kafka Message: ======> \n{}", kafkaMessage);
Map<Object, Object> map = new HashMap<>();
ObjectMapper mapper = new ObjectMapper();
try {
map = mapper.readValue(kafkaMessage, new TypeReference<>() {});
} catch (JsonProcessingException e) {
log.error(e.getMessage());
}
Long targetItemId = Long.parseLong(String.valueOf(Optional.of(map.get("itemId"))
.orElseThrow(ItemNotFoundException::new)));
Integer soldQuantity = (Integer) Optional.of(map.get("quantity"))
.orElseThrow(() -> new IllegalStateException("Not found quantity"));
return itemRepository.findByIdForUpdate(targetItemId)
.switchIfEmpty(Mono.error(new ItemNotFoundException()))
.flatMap(item -> {
item.changeQuantity(item.getQuantity() - soldQuantity);
return itemRepository.save(item);
})
.doOnSuccess(item -> log.info("item({}) process completed", targetItemId))
.then();
}
}
기존 방식에서는 JDBC가 영속성 컨텍스트를 지원하기 때문에 변경감지 기능을 통해 DB를 업데이트해줬었는데
R2DBC는 변경감지 기능을 지원하지 않기 때문에, itemRepository.save(item) 을 추가했습니다.
findByIdForUpdate() 를 새롭게 만들어서 비관적 락을 구현해줬습니다
혹시라도 R2DBC가 Id Column을 못찾는다고 에러를 뱉는다면,,
@Id어노테이션이org.springframework.data.annotation에서 import 된 것인지 확인하세요,,
ItemRepository.java 리팩토링
1
2
3
4
public interface ItemRepository extends R2dbcRepository<Item, Long> {
@Query("SELECT * FROM item WHERE id = :id FOR UPDATE")
Mono<Item> findByIdForUpdate(Long id);
}
@Query 어노테이션을 활용해서 쿼리를 수동으로 작성해주었습니다.
FOR UPDATE 구문을 추가하면 락을 적용할 수 있습니다.
Test Code를 통해 제대로 동작하는지 확인하기
KafkaConsumerTest.java
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
@SpringBootTest(
classes = ItemserviceApplication.class,
webEnvironment = SpringBootTest.WebEnvironment.NONE)
@EmbeddedKafka(partitions = 1, topics = {"db-connection-test"})
@TestInstance(TestInstance.Lifecycle.PER_CLASS)
class KafkaConsumerTest {
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
@Autowired
private ItemRepository itemRepository;
private final ObjectMapper objectMapper = new ObjectMapper();
private final String topic = "db-connection-test";
private final Long itemId = 123L;
// @BeforeEach
// void setUp() {
// // 상품 초기화 (수량 100)
// Item item = new Item(
// itemId,
// "테스트",
// "테스트 상품",
// 100,
// BigDecimal.valueOf(10000),
// 1L
// );
// itemRepository.save(item).block(); // 동기식으로 대기
// }
//
// @AfterEach
// void cleanUp() {
// itemRepository.deleteById(123L).block(); // 전체 삭제
// }
@Test
void 동시성_테스트_메시지10개_전송하면_정확히_차감된다() throws Exception {
Item before = itemRepository.findById(itemId).block();
int messageCount = 10;
ExecutorService executor = Executors.newFixedThreadPool(messageCount);
for (int i = 0; i < messageCount; i++) {
executor.submit(() -> {
try {
Map<String, Object> message = Map.of(
"itemId", itemId,
"quantity", 1
);
String payload = objectMapper.writeValueAsString(message);
kafkaTemplate.send(topic, payload);
} catch (Exception e) {
throw new RuntimeException(e);
}
});
}
executor.shutdown();
executor.awaitTermination(5, TimeUnit.SECONDS);
// Kafka 소비 후 수량이 줄었는지 기다림 (최대 3초 대기)
Thread.sleep(3000);
// 검증
Item result = itemRepository.findById(itemId).block();
assertNotNull(result);
assertEquals(before.getQuantity() - 10, result.getQuantity()); // 기존보다 10 작은 값
}
}
비동기식으로 동작해서 그런지,,BeforeEach나 AfterEach가 제대로 동작을 안 해서
일단 임시방편으로 작성한 테스트코드입니다,,
결과
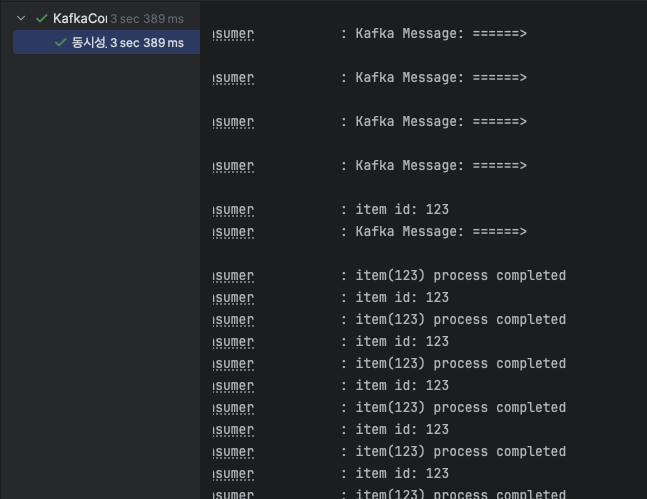
성공!!
참고 자료