MSA 구현하기(14) Fin. - 쿠버네티스에 배포하기 (CI/CD 구축까지) (feat. k8s, Jenkins, ArgoCD)
Skala 과정에서 마이크로 서비스 아키텍처 구조에 대해 새롭게 알게 되었습니다.
배운 것을 실제로 구현해보기 위해 이 여정을 시작하기로 했습니다.
처음 글부터 보러가기
이 글에서는 단순한 쿠버네티스 실습을 넘어, MSA 아키텍처를 쿠버네티스에 적용하고, CI/CD를 구축하기까지의 여정을 기록하였니다.
프로젝트 개요
- 목표: Kubernetes 환경에서 MSA 서비스를 띄워보고, 배포 자동화까지 구축하기
- 사용 기술 스택
- Backend: Java Spring Boot
- Frontend: Vue.js
- Infrastructure: Kubernetes, Docker, Jenkins, ArgoCD
- Database: MariaDB
- Message Broker: Kafka
기존에 개발하고 있던 MSA 프로젝트를 k8s에 올려, 지속적인 통합 및 배포 자동화를 해보기로 했습니다.
(힘들어요)
기존 개발여정이 궁금하신 분들은 여기를 참고해주세요.
MSA 아키텍처 설계
- 마이크로 서비스
- API Gateway(Aggregation 서비스)
- 사용자 서비스
- 주문 서비스
- 상품 서비스
- 서비스 간 통신: REST API / Kafka 이벤트 기반 통신
- 사용자, 주문, 상품 서비스에 대한 DB도 모두 분리
💡 기존에 설계해 둔 아키텍처에서
Eureka Server만 사용하지 않습니다!
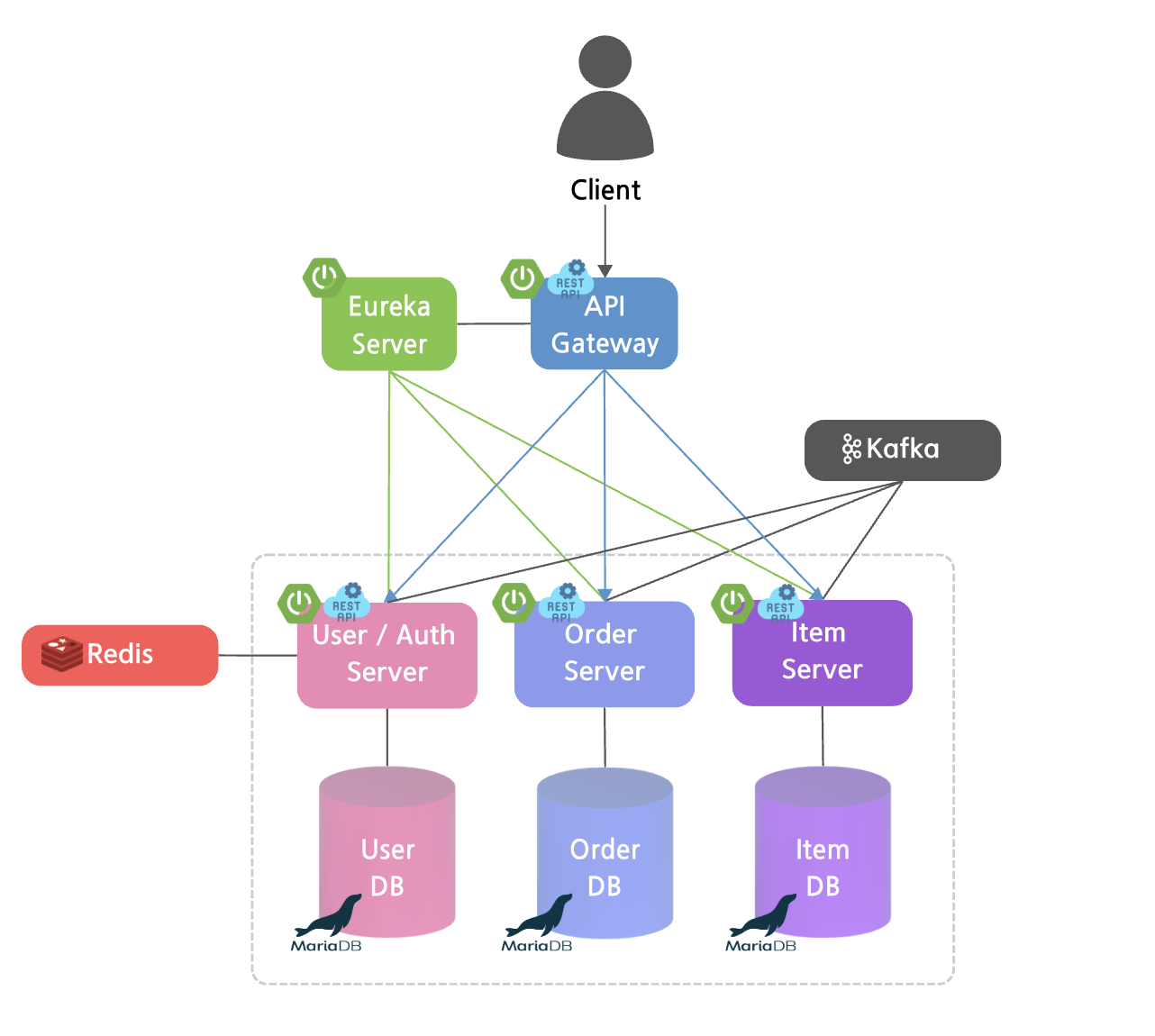
Eureka Server를 사용하지 않은 이유?
쿠버네티스에서는 Service 를 통해 각 pod가 엔드포인트를 갖게 할 수 있습니다. (단, 클러스터 내부에서만 해당 엔드포인트를 사용할 수 있습니다.)
이 엔드포인트를 이용하면, Eureka Server가 서버를 찾아주지 않아도, 엔드포인트만 알고 있다면 각 서비스를 찾을 수 있고 Eureka 보다 더 빠르게 서버가 등록되기 때문에 이를 사용하지 않았습니다.
API Gateway를 사용한 이유?
원래라면 API Gateway는 로드 밸런싱을 위해 만드는 서버이기 때문에 쿠버네티스를 사용할 경우, 쿠버네티스가 그 기능을 지원하기 때문에 필요하지 않지만, 저는 그 기능 이외에 Aggregation(BFF) 기능 까지 넣어두었기 때문에 서버를 뺄 수 없었습니다(ㅜ.ㅜ)
기본 명령어 정리
pod 배포 시
- kubectl apply -f deploy.yaml
service 등록 시
- kubectl apply -f service.yaml
그외 다른 yaml 파일을 적용할 때에는 모두 kubectl apply -f {파일명} 명령어를 실행하면 됩니다!
생성된 것(?)들 확인하기
- kubectl get pod
pod 이외에 service, deploy, configmaps, ingress 등을 입력할 수 있습니다.
위 명령어들을 실행하면 생성된 모든 생성물(?)들을 확인할 수 있습니다.
Kubernetes에 pod 띄우기
쿠버네티스에 pod를 띄우기 위해서는
- 소스코드를 도커 이미지로 만든다
- 도커 이미지를 업로드한다.(원격 도커 이미지 저장소에 업로드합니다)
- 쿠버네티스 서버에서
deploy.yaml이 실행되며 원격 저장소에서 도커 이미지를 받아와 pod 내부에 컨테이너를 실행하여 pod를 띄운다.
위 과정이 필요합니다.
Dockerfile 생성하기
저는 Spring boot, Vue.js를 적용하기 위해 둘의 Dockerfile을 다르게 설정해두었습니다.
[ spring boot의 Dockerfile ]
1
2
3
4
5
6
7
8
9
10
11
12
# 베이스 이미지로 OpenJDK 17 버전의 JRE 이미지 사용
FROM openjdk:17-jdk-slim
WORKDIR /app
# 외부에서 컨테이너의 19901 포트에 접근할 수 있도록 설정
EXPOSE 19901
# 애플리케이션의 jar 파일을 컨테이너에 추가
COPY ./gatewayserver/target/api-gateway-0.0.1-SNAPSHOT.jar app.jar
# 애플리케이션 실행
ENTRYPOINT ["java","-Djava.security.egd=file:/dev/./urandom","-jar","app.jar"]
[ vue.js의 Dockerfile ]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# Build stage
FROM node:20.14.0 AS build-stage
WORKDIR /app
COPY package*.json ./
RUN npm pkg set type=module
RUN npm install
COPY . .
RUN npm run build
# Production stage
FROM nginx:stable-alpine
# Add our custom nginx config
COPY default.conf /etc/nginx/conf.d/
COPY --from=build-stage /app/dist /etc/nginx/html
EXPOSE 80
CMD ["nginx", "-g", "daemon off;"]
[ Vue.js를 위한 nginx html 설정용 default.conf ]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
server {
listen 80;
location /api/ {
proxy_pass http://sk067-my-apigateway:19901/;
proxy_http_version 1.1;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
}
location / {
alias /etc/nginx/html/;
try_files $uri $uri/ /index.html;
if ($request_method !~ ^(GET|POST|PUT|DELETE|OPTIONS)$) {
return 405;
}
}
}
💡 만약 ARM64(M1, M2, … 맥북) 기반 노트북 사용자라면,
docker build 시buildx명령어를 통해 빌드해주세요..!!
1
2
3
4
sudo docker buildx build \
--platform linux/amd64 \
-t {원격 저장소 url}/{이미지 이름}:{이미지 버전} \
--push .
저는 위 명령어를 통해 빌드했습니다!
configmap.yaml 파일 생성하기
저는 우선 application.yml을 통해 직접 빌드하도록 했었는데,
configmap을 적용하지 않으면 application-prod, application-dev 이렇게 두 가지의 프로필을 통해 개발용 변수와 배포용 변수를 관리해야만 했습니다.
매번 코드에 직접 들어가서 수정하는 것이 귀찮았기 때문에 configmap.yaml 을 적용해서 환경변수를 훨씬 유동적으로 바꿀 수 있도록 했습니다.
저는 쿠버네티스를 개발용으로 사용하지 않아서 하나의 configmap만 생성했지만
configmap도 개발용과 배포용으로 빌드할 수 있습니다.
[ configmap.yaml ]
1
2
3
4
5
6
7
8
9
# gateway-configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: gateway-config
data:
USER_URI: http://sk067-my-userserver:8081
ORDER_URI: http://sk067-my-orderserver:8082
ITEM_URI: http://sk067-my-itemserver:8083
각 마이크로 서비스의 uri를 설정하는 변수를 configmap을 통해 적용하였습니다.
Ingress.yaml 파일 생성하기
Ingress?
Service와 달리 Ingress는 외부에 엔드포인트를 설정해주는 기능입니다.
tls 설정을 함께 사용하면 따로 복잡한 설정 과정 없이, 보유한 도메인의 하위 도메인을 자동으로 CA 인증받도록 할 수 있습니다.
[ ingress.yaml ]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
annotations:
cert-manager.io/cluster-issuer: letsencrypt-prod
name: ${USER_NAME}-mypang-ingress
namespace: ${NAMESPACE}
spec:
ingressClassName: public-nginx
rules:
- host: ${USER_NAME}-mypang.skala25a.project.skala-ai.com
http:
paths:
- backend:
service:
name: ${USER_NAME}-${SERVICE_NAME}
port:
number: 19901
path: /
pathType: Prefix
tls:
- hosts:
- ${USER_NAME}-mypang.skala25a.project.skala-ai.com
secretName: ${USER_NAME}-mypang-tls-secret
이렇개 하고 ingress.yaml을 적용시켜주면 등록해 둔 url로 접속이 가능합니다!
Liveness & Readiness Probe 적용
Actuator 적용하기
Liveness와 Readiness는 서버의 실제 API 경로로 일정 간격을 두고 계속해서 요청을 보낸 후,
임계값 이상의 오류가 발생하지 않는다면 정상적으로 도와주도록 만드는 패턴입니다.
Actuator는 Swagger와 비슷하게 복잡한 설정 없이도, 자동으로 서버의 상태를 알려주는 기능이 있는 라이브러리입니다.
실제 actuator를 적용하게 되면, 서버의 오류가 발생하는 것을 쉽게 컨트롤할 수 없기 때문에
제가 직접 만든 API를 사용해서 actuator를 흉내내보았습니다.
[ CustomActuatorController.java ]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
@RestController
@RequestMapping("/actuator")
public class CustomActuatorController {
private final AtomicBoolean isReady = new AtomicBoolean(true);
private final AtomicBoolean isLive = new AtomicBoolean(true);
@GetMapping("/health")
public Mono<ResponseEntity<Map<String, Object>>> health() {
Map<String, Object> health = new HashMap<>();
if (isLive.get()) {
health.put("status", "UP");
return Mono.just(ResponseEntity.ok(health));
} else {
health.put("status", "DOWN");
return Mono.just(ResponseEntity.status(HttpStatus.BAD_REQUEST).body(health)); // 400
}
}
@GetMapping("/ready")
public Mono<ResponseEntity<Map<String, Object>>> readiness() {
Map<String, Object> status = new HashMap<>();
if (isReady.get()) {
status.put("status", "READY");
return Mono.just(ResponseEntity.ok(status));
} else {
status.put("status", "NOT READY");
return Mono.just(ResponseEntity.status(HttpStatus.SERVICE_UNAVAILABLE).body(status)); // 503
}
}
@PostMapping("/health/{flag}")
public Mono<ResponseEntity<Map<String, Object>>> setReadiness(@PathVariable boolean flag) {
isLive.set(flag);
return health();
}
@PostMapping("/ready/{flag}")
public Mono<ResponseEntity<Map<String, Object>>> setLiveness(@PathVariable boolean flag) {
isReady.set(flag);
return readiness();
}
}
이 컨트롤러를 작성한 후, API 테스트 꼭 해보세용,.,.,.!
Liveness Probe
- 정의: 컨테이너가 정상 동작 중인지를 판단
- 적용 방법 예시:
1 2 3 4 5 6 7 8
# deploy.yaml 파일 중 일부 livenessProbe: httpGet: path: /actuator/health port: 8080 initialDelaySeconds: 5 # startupProbe 처리 후 5초 뒤 탐침 실행 periodSeconds: 3 # 3초 주기로 탐침 실행 failureThreshold: 2 # 2번 이상 실패 시 pod 종료, pod Replace 혹은 pod Restart 실행
Readiness Probe
- 정의: 트래픽을 받을 준비가 되었는지 판단
- 적용 방법 예시:
1 2 3 4 5 6 7 8
# deploy.yaml 파일 중 일부 readinessProbe: httpGet: path: /actuator/ready port: 8080 initialDelaySeconds: 5 # startupProbe 처리 후 5초 뒤 탐침 실행 periodSeconds: 3 # 3초 주기로 탐침 실행 failureThreshold: 2 # 2번 이내 정상일 경우 엔드포인트를 등록함, 그렇지 않을 경우 엔드포인트 제거
🔍 혹시 Probe 적용을 했음에도 불구하고 정상적으로 동작하지 않는다면, 저의 경우에는 이렇게 해결했습니다!
- 올바른 path가 작성되어 있는지 확인해보기
deploy.yaml내부, Probe를 설정하기 전에1 2
ports: - containerPort: (포트)
작성하기
적용 화면
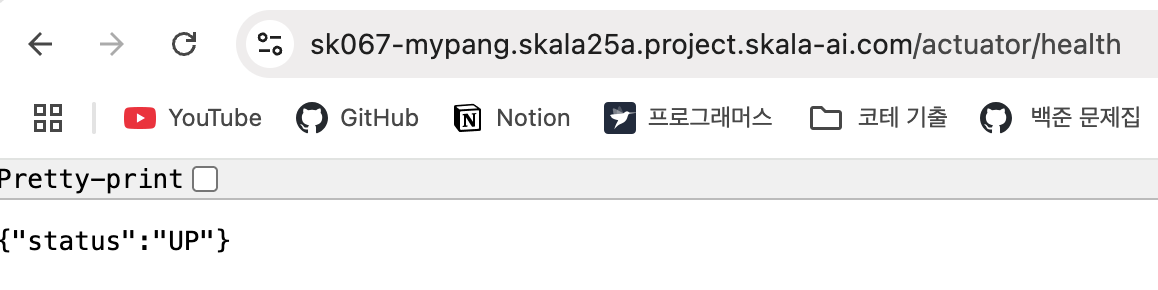
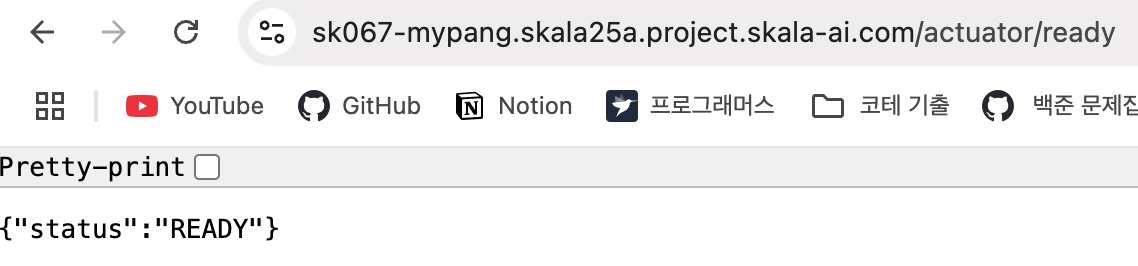
health와 ready 모두 정상적으로 떠 있습니다.
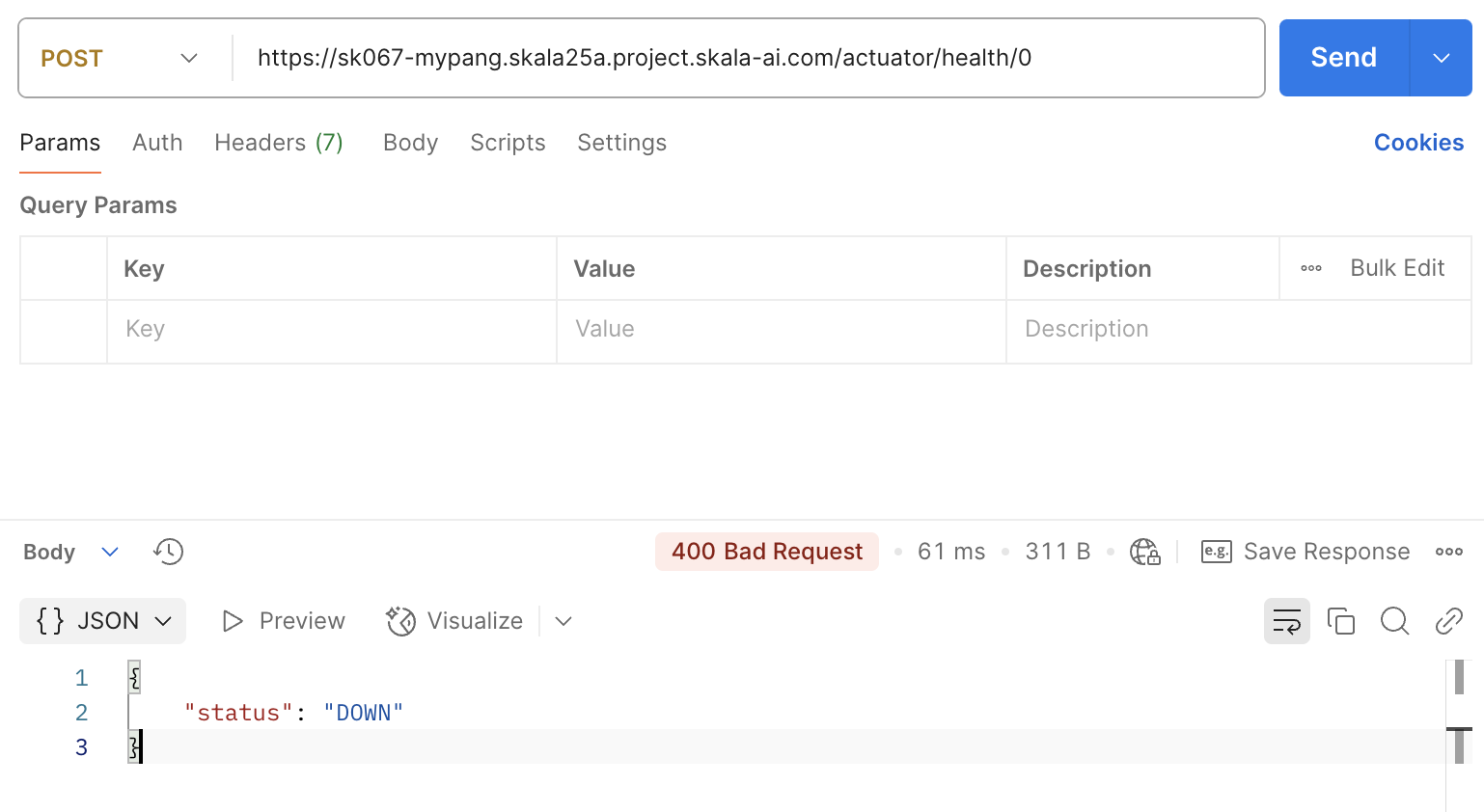
여기서 health를 DOWN 상태로 바꿔보면

pod에 문제가 생겨 재시작한 것을 확인할 수 있습니다.
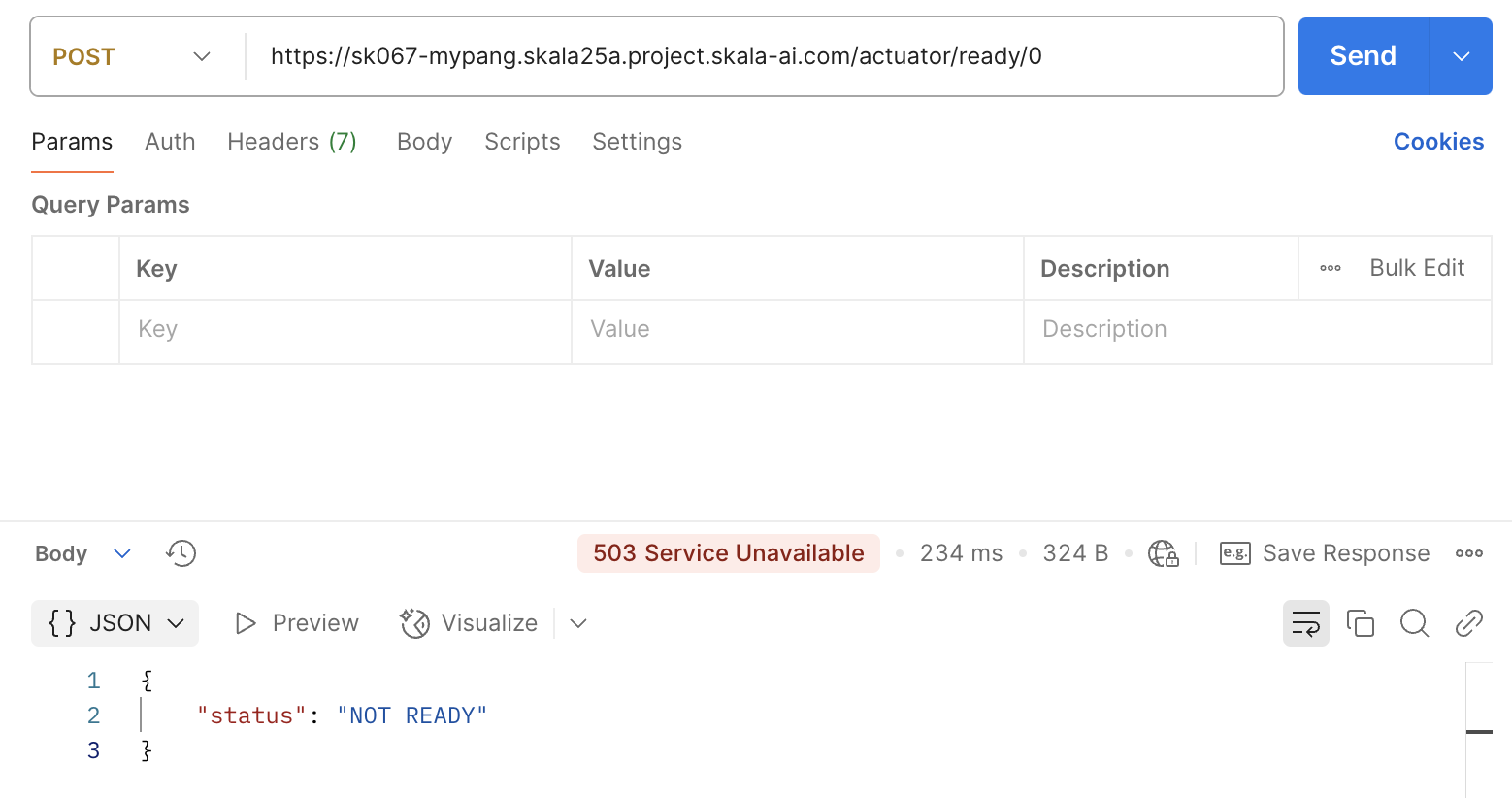
이제 ready를 NOT READY 상태로 바꿔보면

재시작 여부가 보이지는 않지만, 재시작을 하지 않고 READY 상태만 0/1 로 바뀐 모습을 확인할 수 있습니다.
Startup Probe를 적용하지 않은 이유?
Startup Probe는 pod내 컨테이너가 정상적으로 띄워지기 전(Success 전)까지 다른 Probe를 실행하지 않도록 지원해주는 기능입니다.
하지만,,
서버의 부팅이 느릴 일이 거의 없습니다.
Spring boot는 5 ~ 10초 안에 부팅이 가능하고, 복잡한 초기화 과정이 없었기 때문에 initialDelaySeconds 를 통해 서버 실행 전 충분한 텀을 확보할 수 있습니다.
따라서, Startup Probe를 적용하지 않았습니다!
최종 deploy.yaml 및 service.yaml 작성하기
[ deploy.yaml ]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
apiVersion: apps/v1
kind: Deployment
metadata:
name: ${USER_NAME}-${SERVICE_NAME}
namespace: ${NAMESPACE}
spec:
replicas: 2 # pod가 2개 띄워집니다.
selector:
matchLabels:
app: ${USER_NAME}-${SERVICE_NAME}
template:
metadata:
labels:
app: ${USER_NAME}-${SERVICE_NAME}
spec:
serviceAccountName: default
containers:
- name: ${IMAGE_NAME}
image: ${DOCKER_REGISTRY}/${USER_NAME}-${IMAGE_NAME}:${VERSION}
imagePullPolicy: Always
# 이 부분은 다른 deploy에는 적용되었지만 api gateway 서버에서는 이 설정을 사용하면 제대로 구동이 되지 않아 제외하였습니다.
# resources:
# requests:
# cpu: "100m"
# limits:
# cpu: "500m"
env:
- name: USER_NAME
value: ${USER_NAME}
- name: NAMESPACE
value: ${NAMESPACE}
- name: USER_URI
valueFrom:
configMapKeyRef:
name: gateway-config
key: USER_URI
- name: ORDER_URI
valueFrom:
configMapKeyRef:
name: gateway-config
key: ORDER_URI
- name: ITEM_URI
valueFrom:
configMapKeyRef:
name: gateway-config
key: ITEM_URI
ports:
- containerPort: 19901
livenessProbe:
httpGet:
path: /actuator/health
port: 19901
initialDelaySeconds: 5
periodSeconds: 3
failureThreshold: 2
readinessProbe:
httpGet:
path: /actuator/ready
port: 19901
initialDelaySeconds: 5
periodSeconds: 3
failureThreshold: 2
저는 스크립트를 사용해서 ${변수} 를 치환할 수 있도록 yaml 파일을 만들었습니다.
그래서 따로 env.properties를 만들었는데, 직접 yaml을 작성해도 전혀 상관없습니다!
[ service.yaml ]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
apiVersion: v1
kind: Service
metadata:
name: ${USER_NAME}-${SERVICE_NAME}
namespace: ${NAMESPACE}
spec:
selector:
app: ${USER_NAME}-${SERVICE_NAME}
ports:
- name: http
protocol: TCP
port: ${CONTAINER_PORT}
targetPort: ${CONTAINER_PORT}
type: ClusterIP
이렇게 deploy와 service를 작성한 후에 각 yaml을 적용시키면
pod가 띄워지고, 엔드포인트가 등록됩니다!
저는 총 12개의 pod를 띄웠습니다.(API Gateway(2), User/Orde/Item Server(각 2개씩 6개), DB(1), Kafka(1), Front-UI(2))
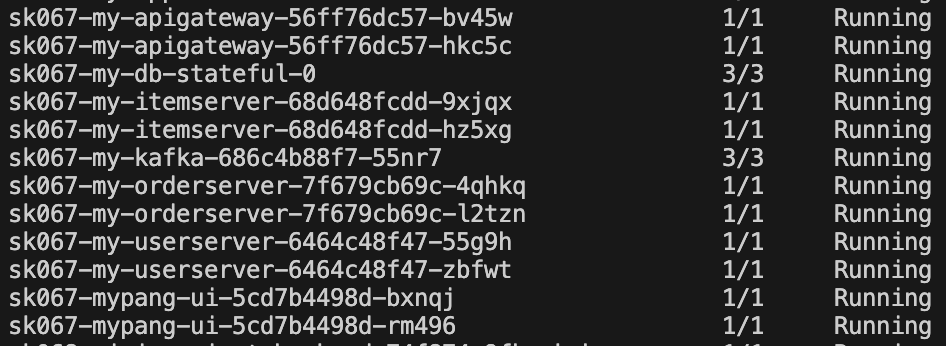
replica를 2개로 설정해둬서 이렇게 pod가 2개씩 떴습니당
추후에는 현재 적용중인 비관적락 대신 분산락을 적용 해볼까 생각 중입니다!
모든 마이크로 서비스에 swagger 및 actuator, probe, configmap, ingress를 적용한 것은 아닙니다,,
모두 API Gateway 서버에만 적용했습니다!(ingress는 front 서버에도 적용해두었습니다)
CI/CD는 모든 서버(Spring boot와 Vue.js 서버)에 적용했습니다.
Swagger를 통한 API 문서화
Springdoc / Swagger UI 설정 방법
저의 경우에는 일반적인 Spring 개발자들이 사용하는 mvc가 아닌, webflux 구조를 사용하고 있었기 때문에 스웨거를 적용할 때 레퍼런스가 조금 부족해서 많이 헤맸습니다,,
[ pom.xml ]
1
2
3
4
5
<dependency>
<groupId>org.springdoc</groupId>
<artifactId>springdoc-openapi-starter-webflux-ui</artifactId>
<version>2.8.5</version>
</dependency>
[ SwaggerConfig.java ]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
@Configuration
public class SwaggerConfig {
@Bean
public OpenAPI openAPI() {
SecurityScheme securityScheme = new SecurityScheme()
.type(SecurityScheme.Type.HTTP)
.scheme("bearer")
.bearerFormat("JWT")
.in(SecurityScheme.In.HEADER)
.name("Authorization");
SecurityRequirement securityRequirement = new SecurityRequirement()
.addList("BearerAuth");
return new OpenAPI()
.components(new Components()
.addSecuritySchemes("JWT Token", securityScheme))
.addSecurityItem(securityRequirement)
.info(new Info()
.title("Api Gateway API")
.description("API 문서")
.version("1.0.0"))
.addServersItem(new Server().url("/"));
}
}
이렇게 두 개의 파일만 설정하고 나면
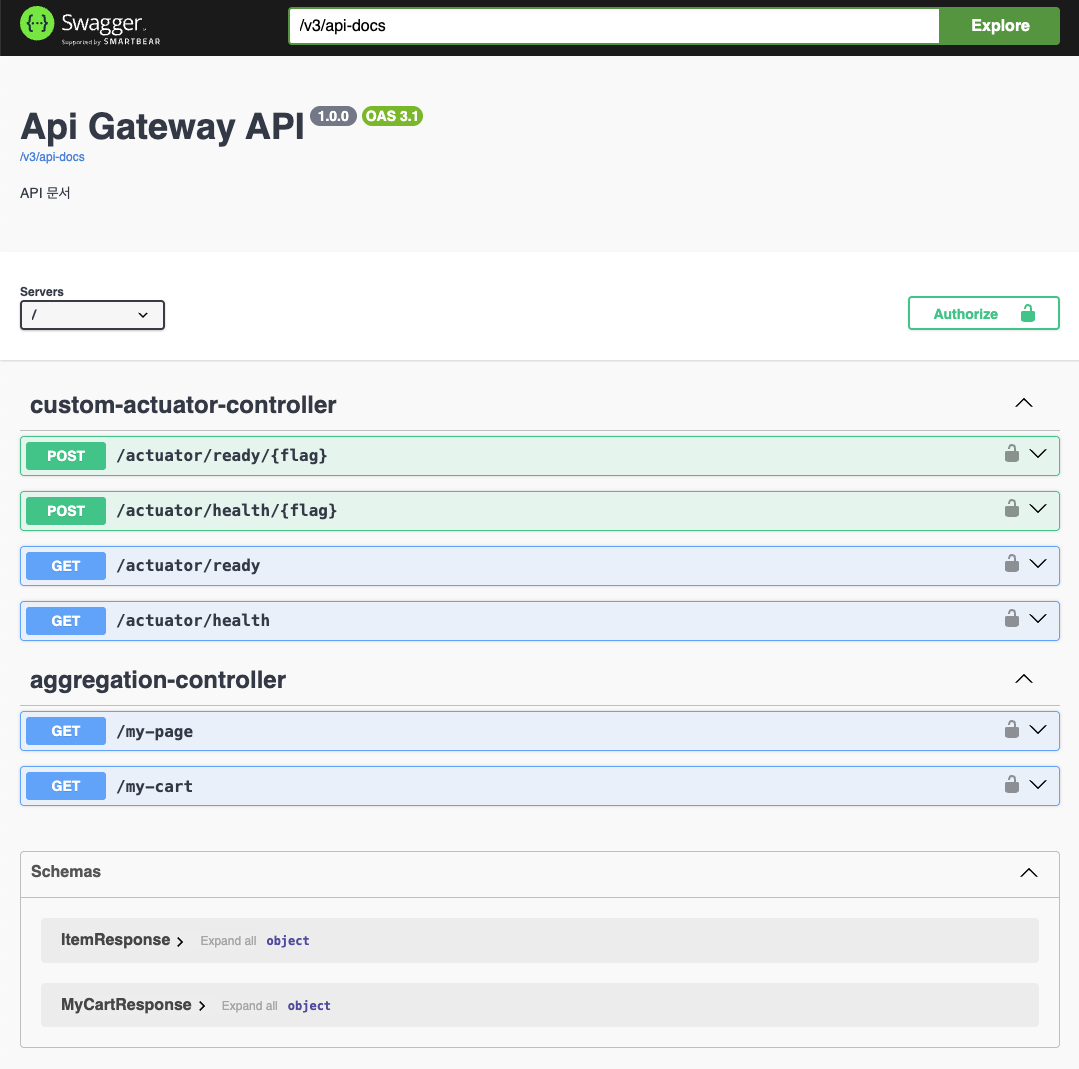
짜잔. 이렇게 Swagger ui를 확인할 수 있습니다!
CI/CD: Jenkins + ArgoCD 구축
Jenkins
Jenkins를 등록하기 위해서는 꽤나 복잡한 절차가 필요한대용,,
우선 저는 교수님꼐서 주신 도커파일을 이용해서 로컬에 Jenkins를 띄웠습니다.
도커 실행 시에 admin 계정이 만들어져서 그 계정을 이용해 파이프라인을 구성했습니다
사전에 설치된 플러그인으로는 (workflow-aggregator, git, git-client, github-branch-source, docker-workflow, pipeline-stage-view, blueocean, credentials-binding, timestamper, job-dsl, configuration-as-code, kubernetes, maven-plugin, junit, htmlpublisher) 가 있습니다.
위 플러그인을 꼭! 모두 설치해야 하는 것이 아니기 때문에 상황에 맞춰 필요한 플러그인들만 설치해도 될 것 같습니다.
저는 Vue.js의 배포도 파이프라인에 추가했기 때문에 추가적으로 Node.js 플러그인을 설치했습니다.
설치 이후 Jenkins 관리 > Tools > NodeJS installations에 구성을 추가 해야 정상적으로 동작합니다.
Credentials도 미리 등록하여 Git에 연결해두어야 합니다!
파이프라인 작성 방식 (
Jenkinsfile예시):1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96
pipeline { agent any environment { GIT_URL = 'https://github.com/Sermadl/devops-source.git' GIT_USER_NAME = 'Sermadl' GIT_USER_EMAIL = 'rlatpdms1014@gmail.com' GIT_BRANCH = 'main' // 또는 master GIT_ID = 'skala-github-id' // Jenkins에 등록한 GitHub credential ID IMAGE_REGISTRY = 'amdp-registry.skala-ai.com/skala25a' IMAGE_NAME = 'sk067-my-apigateway' IMAGE_TAG = '2.0.0' DOCKER_CREDENTIAL_ID = 'skala-image-registry-id' // Harbor 인증 정보 ID } stages { stage('Clone Repository') { steps { git branch: "${GIT_BRANCH}", url: "${GIT_URL}", credentialsId: "${GIT_ID}" // GitHub PAT credential ID } } stage('Build with Maven') { steps{ dir('api-gateway/gatewayserver') { sh 'chmod +x mvnw' sh './mvnw clean package -DskipTests' } } } stage('Docker Build & Push') { steps { dir('api-gateway'){ script { // 해시코드 12자리 생성 def hashcode = sh( script: "date +%s%N | sha256sum | cut -c1-12", returnStdout: true ).trim() // Build Number + Hash Code 조합 (IMAGE_TAG는 유지) def FINAL_IMAGE_TAG = "${IMAGE_TAG}-${BUILD_NUMBER}-${hashcode}" echo "Final Image Tag: ${FINAL_IMAGE_TAG}" docker.withRegistry("https://${IMAGE_REGISTRY}", "${DOCKER_CREDENTIAL_ID}") { def appImage = docker.build("${IMAGE_REGISTRY}/${IMAGE_NAME}:${FINAL_IMAGE_TAG}", "--platform linux/amd64 .") appImage.push() } // 최종 이미지 태그를 env에 등록 (나중에 deploy.yaml 수정에 사용) env.FINAL_IMAGE_TAG = FINAL_IMAGE_TAG } } } } stage('Update deploy.yaml and Git Push') { steps { dir('api-gateway') { script { def newImageLine = " image: ${env.IMAGE_REGISTRY}/${env.IMAGE_NAME}:${env.FINAL_IMAGE_TAG}" def gitRepoPath = env.GIT_URL.replaceFirst(/^https?:\/\//, '') sh """ sed -i 's|^[[:space:]]*image:.*\$|${newImageLine}|g' ./argocd-k8s/deploy.yaml cat ./argocd-k8s/deploy.yaml """ sh """ git config user.name "$GIT_USER_NAME" git config user.email "$GIT_USER_EMAIL" git add ./argocd-k8s/deploy.yaml || true """ withCredentials([usernamePassword(credentialsId: "${env.GIT_ID}", usernameVariable: 'GIT_PUSH_USER', passwordVariable: 'GIT_PUSH_PASSWORD')]) { sh """ if ! git diff --cached --quiet; then git commit -m "[AUTO] Update deploy.yaml with image ${env.FINAL_IMAGE_TAG}" git remote set-url origin https://${GIT_PUSH_USER}:${GIT_PUSH_PASSWORD}@${gitRepoPath} git push origin ${env.GIT_BRANCH} else echo "No changes to commit." fi """ } } } } } } }
위 파이프라인은 저의 상황에 맞게 구성되어 있는 파이프라인이기 때문에 적절하게 바꾸어서 사용하시면 됩니다!
dir('api-gateway') 는 깃 레포지토리 내부에 들어있는 폴더로 들어가서 명령어를 실행하라는 의미로 넣어 둔 코드입니다.
Jenkins의 파이프라인을 실행하는 방법은 2가지가 있습니다.
- ‘Pipeline script from SCM’ 옵션으로 로컬에서 깃에 푸시를 할 때 Jenkins 파이프라인이 실행되도록 git에 파이프라인을 업로드한다.
- ‘Pipeline script’ 옵션으로 파이프라인 스크립트를 직접 등록하여 Jenkins에서 빌드 버튼을 누른다.(제가 사용한 방식입니다.)
저는 2번째 방법을 사용했습니다.
MSA 아키텍처 구조로 구성을 했는데 다음에 나올 ArgoCD 트리거 방식이 깃 변동사항을 이용하는 방법이라 깃에 푸시를 감지했을 때 이 빌드들이 한꺼번에 실행되면 깃 변경 사항을 pull 하지 않아서 push가 되지 않는 문제가 발생하더라고요,,clone 이후 push 이전에 pull 하는 방식으로 해결할 수도 있었습니다만
푸시 한 번에 모든 서버를 재빌드, 재배포 하고 싶지 않았습니다!
위에서 언급했던 것처럼 ArgoCD는 깃의 상태가 변한 것을 감지하고 deploy.yaml 파일을 실행하게 되는데,
Jenkins에서 진행되는 CI 과정을 ArgoCD가 감지하도록 만들기 위해서
- Jenkins가 도커 이미지를 빌드할 때마다 이미지의 버전 뒤에 랜덤한 값을 넣어 깃에 커밋, 푸시하여 깃 변경을 감지하도록 한다.(제가 사용한 방식입니다.)
- Webhook을 사용한다.
하지만 저는 Jenkins가 로컬에 있기 때문에 웹훅을 사용할 수가 없어서 1번 방식을 채택했습니다.
그래서 도커 이미지 버전 뒤에 랜덤한 해시코드를 붙이는 로직이 추가되어 있습니다.
ArgoCD
- 파일 구성
- application.yaml(5개)
- git-repository.yaml(5개)
Jenkins를 사용하여 CI 및 CD까지 할 수 있지만, 배포된 pod가 정상적으로 동작 중인지, git repository에 업로드되어 있는 코드와 sync가 일치하는지 등 pod에 대한 정보를 실시간으로 확인할 수 없습니다. 그래서 저는 ArgoCD도 함께 사용하였습니다.
처음 파일을 구성할 때 깃 Secret을 한 개만 등록해도, application의 이름을 등록하지 않아도 전혀 문제가 없다는 GPT의 말을 믿어버려서 계속해서 OutOfSync 문제가 발생했었습니다,,
이 글을 보는 분들은 꼭 application과 git repo 정보가 담긴 Secret을 일대일로 매핑하세요,,,
절대 application.yaml 파일을 deploy.yaml이 있는 폴더에 함께 두지 마세요……
저도 알고 싶지 않았습니다만, application이 불러올 깃의 정보를 하나하나 매핑시켜줘야 되었습니다.
그리고 deploy.yaml 파일이 있는 폴더에 있는 모든 yaml 파일을 argoCD가 감지해서 자동으로 배포해주는 시스템인 것 같더라고요…?App of Apps라고 뜨더니 전혀 구동이 되지 않는..(뭔가 재귀적인 상황..?)상황이……벌어졌습니다….
그리고 꿀팁. ingress.yaml을 deploy.yaml이 있는 폴더에 함께 두면 ArgoCD UI에 바로가기 버튼이 생깁니다!
[ API Gateway 서버의 applicaiton.yaml ]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: sk067-my-apigateway
namespace: skala-argocd
spec:
destination:
namespace: skala-practice
server: https://96BD83E8CE5CE0396D006BC5CEB350B0.gr7.ap-northeast-2.eks.amazonaws.com
project: class-3
source:
path: api-gateway/argocd-k8s
repoURL: https://github.com/Sermadl/devops-source.git
targetRevision: HEAD
syncPolicy:
automated:
prune: true
selfHeal: true
syncOptions:
- PrunePropagationPolicy=background
[ API Gateway 서버의 git-repository.yaml ]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
apiVersion: v1
kind: Secret
metadata:
name: sk067-repo-1
namespace: skala-argocd
labels:
argocd.argoproj.io/secret-type: repository
type: Opaque
stringData:
name: sk067-my-apigateway
type: git
url: https://github.com/Sermadl/devops-source.git
username: Sermadl
project: class-3
password: { GIT PAT 토큰 }
꼭 stringData.name 필드를 이 Secret이 적용되어야 하는 application의 이름으로 지정해주세요!
최종 결과
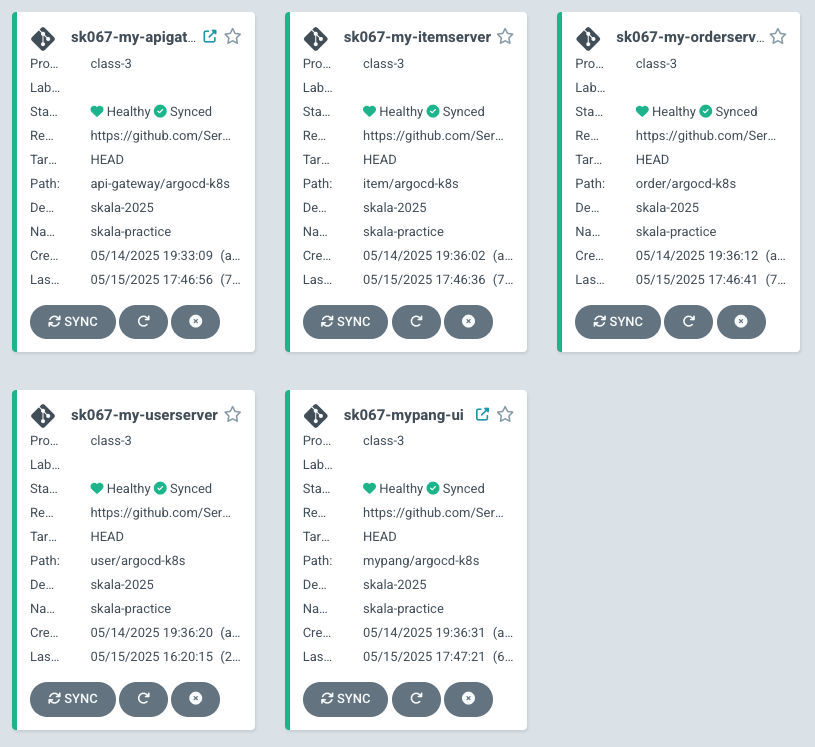
ingress가 적용되어 있는 API Gateway 서버와 Front 서버는 ingress를 적용해두어서, argocd-k8s 폴더에 넣어주었습니다!
그래서 바로가기 버튼이 보이는 것을 확인할 수 있었습니다
[ 보너스(?) 단계 ] DB 및 Kafka 배포..!
MariaDB
Dockerfile로 그냥 띄우다가 이미지를 만들려고 하니 너무 어려웠지만…kafka보다는 훨씬 쉬웠습니다.
(kafka 가만두지 않겠어)
저는 각 마이크로 서비스 한 개당 한 개의 DB를 띄울 것입니다.
DB별 초기 sql 설정도 다르기 때문에 3개의 이미지를 빌드하고 푸시해주었습니다.
제 파일 구조는 다음과 같이 생겼습니다.
각 폴더 안에는 Dockerfile과 init.sql 파일이 있습니다.
docker-build.sh 파일 하나로 3개의 이미지를 동시에 생성하고 싶어서 이렇게 구성해두었습니다.
[ item의 Dockerfile ]
1
2
3
4
FROM mariadb:latest
COPY my.cnf /etc/mysql/conf.d/
COPY item-init.sql /docker-entrypoint-initdb.d/init.sql
RUN chmod 644 /docker-entrypoint-initdb.d/init.sql
제 Spring 서버가 R2DBC 기반이기 때문에 자동으로 테이블이 생성되지 않아 init.sql 파일이 필요했습니다.
테이블 생성해주는 겸 사용자도 따로 생성해주었습니다!
그리고 권한을 꼭 부여해주어야 init.sql의 실행이 되더라고용,,
꼭..설정해주세용…
그리고 사용자도..혹시 모르니까 따로 만들어서 접속하세용……
root 사용자가 localhost에서만 접근 가능하도록 설정되어 있을 수 있습니다.
[ docker-build.sh ]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
#!/bin/bash
VERSION="1.1.0"
sudo docker buildx build \
--platform linux/amd64 \
--no-cache \
-t amdp-registry.skala-ai.com/skala25a/sk067-my-userdb:${VERSION} --push ./user
sudo docker buildx build \
--platform linux/amd64 \
--no-cache \
-t amdp-registry.skala-ai.com/skala25a/sk067-my-orderdb:${VERSION} --push ./order
sudo docker buildx build \
--platform linux/amd64 \
--no-cache \
-t amdp-registry.skala-ai.com/skala25a/sk067-my-itemdb:${VERSION} --push ./item
[ statefulSet.yaml 과 그 안에 있는 service 설정 ]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
# Dockerfile 방식으로 SQL 초기화 수행 (ConfigMap 제거됨)
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: sk067-my-db-stateful
namespace: skala-practice
spec:
serviceName: sk067-my-db-stateful
replicas: 1
selector:
matchLabels:
app: sk067-my-db-stateful
template:
metadata:
labels:
app: sk067-my-db-stateful
spec:
containers:
- name: order-db
image: amdp-registry.skala-ai.com/skala25a/sk067-my-orderdb:1.1.0
ports:
- containerPort: 3306
env:
- name: MYSQL_ROOT_PASSWORD
value: ${ROOT_PASSWORD}
- name: MYSQL_DATABASE
value: ${ORDER_DATABASE}
- name: MYSQL_USER
value: ${USER}
- name: MYSQL_PASSWORD
value: ${PASSWORD}
- name: MYSQL_TCP_PORT
value: "3306"
- name: item-db
image: amdp-registry.skala-ai.com/skala25a/sk067-my-itemdb:1.1.0
ports:
- containerPort: 3307
env:
- name: MYSQL_ROOT_PASSWORD
value: ${ROOT_PASSWORD}
- name: MYSQL_DATABASE
value: ${ITEM_DATABASE}
- name: MYSQL_USER
value: ${USER}
- name: MYSQL_PASSWORD
value: ${PASSWORD}
- name: MYSQL_TCP_PORT
value: "3307"
- name: user-db
image: amdp-registry.skala-ai.com/skala25a/sk067-my-userdb:1.1.0
ports:
- containerPort: 3308
env:
- name: MYSQL_ROOT_PASSWORD
value: ${ROOT_PASSWORD}
- name: MYSQL_DATABASE
value: ${USER_DATABASE}
- name: MYSQL_USER
value: ${USER}
- name: MYSQL_PASSWORD
value: ${PASSWORD}
- name: MYSQL_TCP_PORT
value: "3308"
---
apiVersion: v1
kind: Service
metadata:
name: sk067-order-db
namespace: skala-practice
spec:
selector:
app: sk067-my-db-stateful
ports:
- port: 3306
targetPort: 3306
name: order
---
apiVersion: v1
kind: Service
metadata:
name: sk067-item-db
namespace: skala-practice
spec:
selector:
app: sk067-my-db-stateful
ports:
- port: 3307
targetPort: 3307
name: item
---
apiVersion: v1
kind: Service
metadata:
name: sk067-user-db
namespace: skala-practice
spec:
selector:
app: sk067-my-db-stateful
ports:
- port: 3308
targetPort: 3308
name: user
Stateful Set은 pod가 다시 띄워지더라도 DB의 데이터가 유지되게 해줍니다.
한 pod 당 하나의 컨테이너를 담도록 만들 수도 있었지만, 자원이 너무 낭비되는 것 같아 일단 이런 구조로 만들었습니다.
하다보니 service를 따로 만들어주는게 귀찮아서 그냥 한 파일에 다 넣어버렸습니다 ㅎ.ㅎ
변수가 많이 바뀔 일이 없어서 괜찮을 것 같습니다
Kafka (Bitnami 이미지 활용)
Kafka 역시 기존에는 Dockerfile을 이용해 컨테이너로 띄웠지만, 쿠버네티스 실습을 위해 컨테이너를 pod로 감싸서 올려야 했습니다.
이때, 컨테이너를 pod 1개 당 1개씩 넣어 총 6개(DB 3개, Kafka 3개)의 pod를 배포할 지, pod 1개에 필요한 모든 컨테이너(DB와 Kafka 각 3개씩)를 넣어 총 2개(DB 1개, Kafka 1개)의 pod를 배포할 지 고민이 되었습니다.
만약, 실습이 아닌 실제 배포를 진행하는 상황이었다면 모두 다른 pod에 넣어 배포했을 것 같습니다.
하나의 컨테이너에 오류가 발생하면 모든 컨테이너가 종료될 수도 있기 때문입니다.
하지만 실습을 진행하고 있었고, DB나 Kafka를 배포하는 것이 우선시 되는 상황이 아니었기 때문에 저는 총 2개의 pod를 사용해 배포를 진행하기로 했습니다.
하지만……..kafka 구성을….하는 것이………헷갈렸ㅅ브닏.ㅏ….
[ deploy.yaml ]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
apiVersion: apps/v1
kind: Deployment
metadata:
name: sk067-my-kafka
namespace: skala-practice
spec:
replicas: 1
selector:
matchLabels:
app: sk067-my-kafka
template:
metadata:
labels:
app: sk067-my-kafka
spec:
containers:
- name: kafka-broker-0
image: bitnami/kafka:3.5.1-debian-11-r44
ports:
- containerPort: 9092
- containerPort: 9093
- containerPort: 9094
env:
- name: KAFKA_CFG_BROKER_ID
value: "0"
- name: KAFKA_CFG_NODE_ID
value: "0"
- name: KAFKA_KRAFT_CLUSTER_ID
value: HsDBs9l6UUmQq7Y5E6bNlw
- name: KAFKA_CFG_CONTROLLER_QUORUM_VOTERS
value: "0@localhost:9093,1@localhost:19093,2@localhost:29093"
- name: ALLOW_PLAINTEXT_LISTENER
value: "yes"
- name: KAFKA_CFG_AUTO_CREATE_TOPICS_ENABLE
value: "true"
- name: KAFKA_CFG_LISTENERS
value: "PLAINTEXT://:9092,CONTROLLER://:9093,EXTERNAL://:9094"
- name: KAFKA_CFG_ADVERTISED_LISTENERS
value: "PLAINTEXT://localhost:9092,EXTERNAL://sk067-my-kafka:9094"
- name: KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP
value: "CONTROLLER:PLAINTEXT,EXTERNAL:PLAINTEXT,PLAINTEXT:PLAINTEXT"
- name: KAFKA_CFG_OFFSETS_TOPIC_REPLICATION_FACTOR
value: "1"
- name: KAFKA_CFG_TRANSACTION_STATE_LOG_REPLICATION_FACTOR
value: "1"
- name: KAFKA_CFG_TRANSACTION_STATE_LOG_MIN_ISR
value: "1"
- name: KAFKA_CFG_PROCESS_ROLES
value: "controller,broker"
- name: KAFKA_CFG_CONTROLLER_LISTENER_NAMES
value: "CONTROLLER"
- name: kafka-broker-1
image: bitnami/kafka:3.5.1-debian-11-r44
ports:
- containerPort: 19092
- containerPort: 19093
- containerPort: 19094
env:
- name: KAFKA_CFG_BROKER_ID
value: "1"
- name: KAFKA_CFG_NODE_ID
value: "1"
- name: KAFKA_KRAFT_CLUSTER_ID
value: HsDBs9l6UUmQq7Y5E6bNlw
- name: KAFKA_CFG_CONTROLLER_QUORUM_VOTERS
value: "0@localhost:9093,1@localhost:19093,2@localhost:29093"
- name: ALLOW_PLAINTEXT_LISTENER
value: "yes"
- name: KAFKA_CFG_AUTO_CREATE_TOPICS_ENABLE
value: "true"
- name: KAFKA_CFG_LISTENERS
value: "PLAINTEXT://:19092,CONTROLLER://:19093,EXTERNAL://:19094"
- name: KAFKA_CFG_ADVERTISED_LISTENERS
value: "PLAINTEXT://localhost:19092,EXTERNAL://sk067-my-kafka:19094"
- name: KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP
value: "CONTROLLER:PLAINTEXT,EXTERNAL:PLAINTEXT,PLAINTEXT:PLAINTEXT"
- name: KAFKA_CFG_OFFSETS_TOPIC_REPLICATION_FACTOR
value: "1"
- name: KAFKA_CFG_TRANSACTION_STATE_LOG_REPLICATION_FACTOR
value: "1"
- name: KAFKA_CFG_TRANSACTION_STATE_LOG_MIN_ISR
value: "1"
- name: KAFKA_CFG_PROCESS_ROLES
value: "controller,broker"
- name: KAFKA_CFG_CONTROLLER_LISTENER_NAMES
value: "CONTROLLER"
- name: kafka-broker-2
image: bitnami/kafka:3.5.1-debian-11-r44
ports:
- containerPort: 29092
- containerPort: 29093
- containerPort: 29094
env:
- name: KAFKA_CFG_BROKER_ID
value: "2"
- name: KAFKA_CFG_NODE_ID
value: "2"
- name: KAFKA_KRAFT_CLUSTER_ID
value: HsDBs9l6UUmQq7Y5E6bNlw
- name: KAFKA_CFG_CONTROLLER_QUORUM_VOTERS
value: "0@localhost:9093,1@localhost:19093,2@localhost:29093"
- name: ALLOW_PLAINTEXT_LISTENER
value: "yes"
- name: KAFKA_CFG_AUTO_CREATE_TOPICS_ENABLE
value: "true"
- name: KAFKA_CFG_LISTENERS
value: "PLAINTEXT://:29092,CONTROLLER://:29093,EXTERNAL://:29094"
- name: KAFKA_CFG_ADVERTISED_LISTENERS
value: "PLAINTEXT://localhost:29092,EXTERNAL://sk067-my-kafka:29094"
- name: KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP
value: "CONTROLLER:PLAINTEXT,EXTERNAL:PLAINTEXT,PLAINTEXT:PLAINTEXT"
- name: KAFKA_CFG_OFFSETS_TOPIC_REPLICATION_FACTOR
value: "1"
- name: KAFKA_CFG_TRANSACTION_STATE_LOG_REPLICATION_FACTOR
value: "1"
- name: KAFKA_CFG_TRANSACTION_STATE_LOG_MIN_ISR
value: "1"
- name: KAFKA_CFG_PROCESS_ROLES
value: "controller,broker"
- name: KAFKA_CFG_CONTROLLER_LISTENER_NAMES
value: "CONTROLLER"
---
apiVersion: v1
kind: Service
metadata:
name: sk067-my-kafka
namespace: skala-practice
spec:
selector:
app: sk067-my-kafka
ports:
- name: kafka-0
port: 9094
targetPort: 9094
- name: kafka-1
port: 19094
targetPort: 19094
- name: kafka-2
port: 29094
targetPort: 29094
엄청나죠? ^.^
기존에는 컨테이너 3개를 활용해서 띄웠기 때문에 포트 충돌이 안 났었는데,
이번에는 포트 충돌이 일어나다 보니..정말 너무나도…..디버깅하기 어려웠습니다……
사실 처음에 안될 때는 도대체 뭐가 문제인 것인지 짐작이 안 갔었는데
pod를 올려놓고 이제 서버와 연결하려고 port를 연결할 때
그제서야 포트가 충돌되고 있다는 것을 깨달았습니다.
ㅜㅜ.
아무튼 잘 해결했다는 해피 엔딩,,
Spring에서 엔드포인트 사용해서 연결하기
localhost 대신 엔드포인트를 적용해주면 이제 진짜진짜 적용 끝입니다!
1
2
3
4
5
spring.application.name=order-service
spring.r2dbc.url=r2dbc:mariadb://sk067-order-db:3306/orders?allowPublicKeyRetrieval=true&useSSL=false
spring.r2dbc.username={유저}
spring.r2dbc.password={비밀번호}
server.port=8082
이렇게 해주면 적용 끝! 입니다 ㅎㅎ
엔드포인트는 Service의 이름으로 등록되어 있습니다. 혹시라도 헷갈리시면 k get service 로 엔드포인트 확인하면 됩니당
마치며
- 가장 어려웠던 점
일단 디버깅이 정말 어렵다..? 는 점…..? CLI에서 하는 모든 것이 그렇듯이
에러 메시지가 모든 것을 알려주지 않아서 디버깅하기가 너무 어려웠습니다…
그래도 열심히 지피티, 퍼플렉시티와 함께 디버깅했습니다. 아자.
제가 겪었던 거의 모든 오류에 대한 해결 방법은 위에 잘 찾아보시면 있습니다,,
- CI/CD를 구축하면서 느끼던 자동화의 중요성
일단 전에 github action으로 CI/CD를 구축했을 때에도 정말 편리하다고 생각했지만
Jenkins와 ArgoCD를 사용한 지금도 정말정말 편리한 기능이라고 생각합니다.
무려 서버의 구동 관리를 자동화해주는 k8s를 구축하는 deploy 등 모든 yaml 파일을 자동으로 관리해주는 ArgoCD의 Sync를 자동으로 맞춰주는 Jenkins까지……
역시 개발자들은 자동화에 미쳐(?)있다는 것을 여실히 깨달은 실습이었습니다.
- 다음 과제?
2개의 pod를 띄웠으니, 거기서 생길 수 있는 DB 일관성 문제를 해결하기 위해 분산락 적용에 도전해볼까 합니다…!
참고 자료
놀랍게도 모든 것은 교수님의 강의자료에 있었습니다.
좋은 강의자료 만들어주셔서 감사합니다!
🤓