API Gateway에서 GraphQL to REST API로 요청 변환하기 - Aggregation 시작하기 (feat. Aggregation, MSA)
Skala 과정에서 마이크로 서비스 아키텍처 구조에 대해 새롭게 알게 되었습니다.
배운 것을 실제로 구현해보기 위해 이 여정을 시작하기로 했습니다.
처음 글부터 보러가기
API Gateway 서버에서 각 마이크로 서비스로부터 요청하여 받은 데이터를 조합해서 MSA의 단점을 보완해보고자 합니다.
그래서 먼저 GraphQL로 받은 요청을 REST API로 변환하는 것부터 시작해보겠습니다.!
각 마이크로 서비스 간에서는 REST API를 통해 GraphQL보다 빠른 속도로 처리를 하고,
API Gateway 서버에서 마이크로 서비스에서 받은 응답을 사용자가 필요로 하는 데이터로 가공해주는 역할을 수행하도록 만들어보기로 했습니다.
굉장히 좋은 구조는 아닌 것 같지만(진짜 안 좋았음 <- 바로 다음글에서 구조를 변경합니다,,) 나름대로 이 구조를 취한 이유가 있습니다,,
Aggregation?
| 개념 | 설명 |
|---|---|
| 주요 목적 | 여러 마이크로서비스에서 데이터를 가져와 하나의 응답으로 합쳐클라이언트가 여러 개의 API를 호출하지 않고, 하나의 요청으로 필요한 데이터를 받을 수 있도록 함 |
| 구현 방식 | API Gateway에서 직접 처리 또는 별도의 Aggregation 서버를 두어 처리 |
| 이점 | 네트워크 요청 감소, 응답 속도 최적화, 클라이언트 코드 단순화 |
| 단점 | Aggregation 로직이 복잡해질 경우 성능 저하 가능 |
서버 간 GraphQL로 소통하는 것이 성능 부분에서 좋지 않을 것 같았고,
GraphQL로 응답을 한 번에 받아보고 싶어서 어떤 방법이 좋을까 정말 많이 찾아보았는데,
API Gateway 혹은 개별 Aggregation 서버에서 각 마이크로 서비스로 요청을 받아와 응답을 가공하는 방법이 있다고 해서 이 기술에 대해 관심을 가지게 되었습니다.
실제로 넷플릭스에서는 API Gateway에서 이러한 기능을 수행하도록 구현한 것 같았습니다.(GraphQL로 모든 서버가 통신하는 것 같습니다.)
기존 Federated 엔진을 사용하는 방법과의 차이점
| 비교 항목 | MariaDB Federated 엔진 | Aggregation 기술 |
|---|---|---|
| 개념 | 원격 DB의 테이블을 로컬 DB 테이블처럼 사용하여 JOIN 수행 | 여러 마이크로서비스의 데이터를 API 요청을 통해 조합 |
| 데이터 처리 위치 | DB 레벨에서 직접 JOIN 연산 수행 | API 계층에서 여러 마이크로서비스 데이터를 병합 |
| 성능 | 단일 DB에서 JOIN 시 최적화 가능하지만, 원격 DB 연산 시 네트워크 병목 발생 가능 | 비동기 병렬 요청을 통해 네트워크 지연을 줄이고 성능 최적화 가능 |
| 트랜잭션 관리 | JOIN 연산이 가능하지만, 원격 테이블 간 트랜잭션 관리는 어려움 | 개별 API 호출로 트랜잭션이 분리됨 (SAGA 패턴 활용 가능) |
| 데이터 최신성 | 실시간 데이터 조회 가능 | API 요청을 기반으로 데이터 병합 (캐싱 적용 가능) |
| 확장성 | DB 스키마 변경 시 JOIN 쿼리 수정 필요 | 서비스 간 독립성 유지 가능, 새로운 마이크로서비스 추가 용이 |
| 클라이언트별 응답 최적화 | 고정된 SQL 쿼리 결과 반환 | 클라이언트 요구에 맞춰 응답 데이터 필터링 및 변환 가능 |
| 네트워크 부하 | 원격 DB 호출 시 네트워크 I/O 부하 발생 가능 | 병렬 API 요청을 통해 네트워크 지연 최소화 가능 |
| 기능 확장성 | JOIN 쿼리로 확장 가능하지만, 복잡한 비즈니스 로직 처리는 어려움 | API 계층에서 데이터 조합, 변환, 캐싱, 로깅 등 추가 가능 |
| 보안 | DB 계층에서 권한 관리 필요 | API Gateway 또는 Aggregation 서버에서 인증/인가 관리 가능 |
| 적용 사례 | 단순한 데이터 JOIN이 필요한 경우 | 다양한 마이크로서비스 데이터를 조합해야 하는 경우 |
기존 구조는 DB에서 직접 원격 데이터베이스에 요청하여 테이블을 복제(?)하는 방식이었지만,
Aggregation 기술을 적용한다면, Federated 엔진을 사용하지 않아도 되어 DB 구조가 바뀌더라도 계속해서 init.sql 파일을 수정하지 않아도 된다는 이점(!!)까지 생겼습니다. ☺️
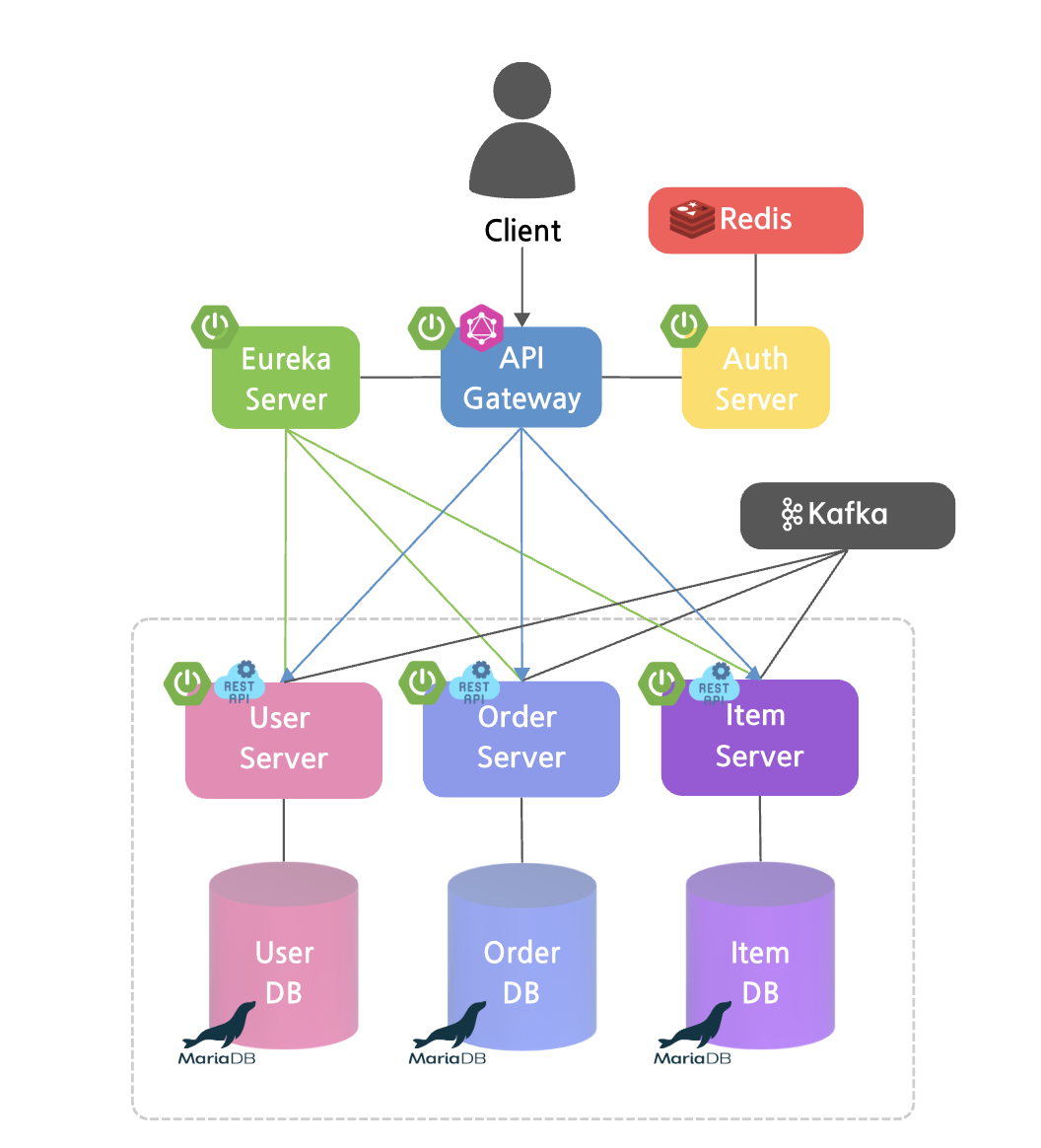
Aggregation이 적용된 진짜 최종 시스템 아키텍처
API Gateway 서버의 API로 요청이 들어오면,
컨트롤러에서 cloud gateway에 등록된 Eureka 서버로 개별 요청을 보낸 후 그 요청을 사용자가 원하는 데이터 구조로 변환해 줄 것입니다.
마치며
구현하게 될 MSA 아키텍처에 대해 굉장히 많은 고민을 하다보니
알게 된 정보가 너무 많아서 정리가 안 됐었는데 교수님과 고민을 공유한 이후에야 머릿속에 각 기술들이 정리가 된 것 같습니다..
이전 글에 현재 아키텍처와 조금 맞지 않는 부분이 있더라도 시행착오를 겪었던 과정이라고 생각해주세요..ㅎㅎ..
글의 내용은 간결하게 작성되었더라도..아키텍처에 대해 거의 3일 내내 고민한 것 같습니다..ㅜㅜ
Aggregation 기술과 유사한 BFF 패턴도 추후에 시간이 있다면 다뤄보도록 하겠습니다!
바로 다음 글에서 본격적으로 마이크로서비스들과 유기적으로 통신하는 코드를 작성해보겠습니다!! 👏 💪
참고 자료